AInsights: Executive-level insights on the latest in generative AI…
OpenAI released a reference guide to improve results from ChatGPT or any generative AI platform. These methods aren’t mutually exclusive. You can use many of them in combination for greater effect.
The point is, experiment!
To help, I captured the high level prompts and each series of supporting pillars in a simple infographic. You can download it here.
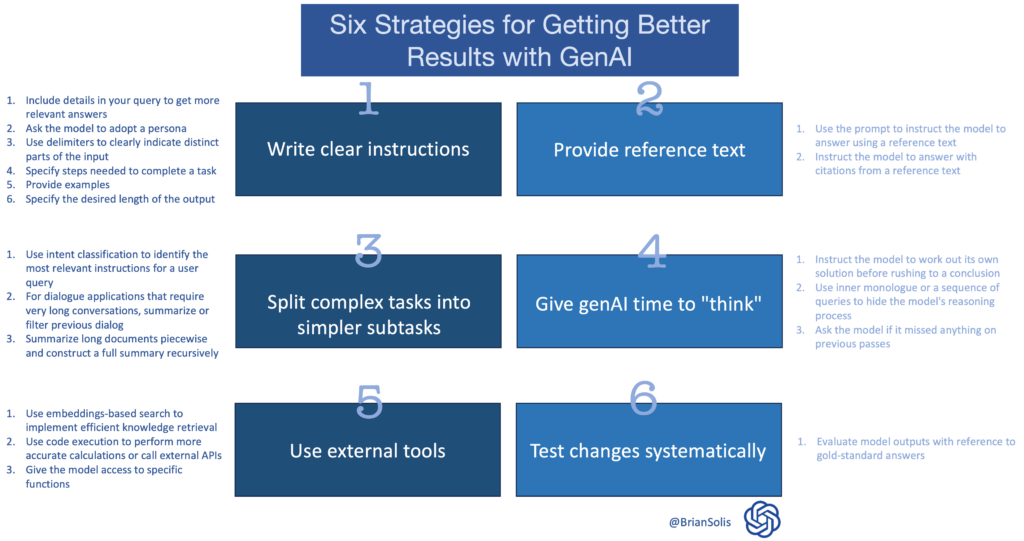
1) Write clear instructions
These models can’t read your mind. If outputs are too long, ask for brief replies. If outputs are too simple, ask for expert-level writing. If you dislike the format, demonstrate the format you’d like to see. The less the model has to guess at what you want, the more likely you’ll get it.
Tactics:
- Include details in your query to get more relevant answers
- Ask the model to adopt a persona
- Use delimiters to clearly indicate distinct parts of the input
- Specify the steps required to complete a task
- Provide examples
- Specify the desired length of the output
2) Provide reference text
Language models can confidently invent fake answers, especially when asked about esoteric topics or for citations and URLs. In the same way that a sheet of notes can help a student do better on a test, providing reference text to these models can help in answering with fewer fabrications.
Tactics:
- Instruct the model to answer using a reference text
- Instruct the model to answer with citations from a reference text
3) Split complex tasks into simpler subtasks
Just as it is good practice in software engineering to decompose a complex system into a set of modular components, the same is true of tasks submitted to a language model. Complex tasks tend to have higher error rates than simpler tasks. Furthermore, complex tasks can often be re-defined as a workflow of simpler tasks in which the outputs of earlier tasks are used to construct the inputs to later tasks.
Tactics:
- Use intent classification to identify the most relevant instructions for a user query
- For dialogue applications that require very long conversations, summarize or filter previous dialogue
- Summarize long documents piecewise and construct a full summary recursively
4) Give the model time to “think”
If asked to multiply 17 by 28, you might not know it instantly, but can still work it out with time. Similarly, models make more reasoning errors when trying to answer right away, rather than taking time to work out an answer. Asking for a “chain of thought” before an answer can help the model reason its way toward correct answers more reliably.
Tactics:
- Instruct the model to work out its own solution before rushing to a conclusion
- Use inner monologue or a sequence of queries to hide the model’s reasoning process
- Ask the model if it missed anything on previous passes
5) Use external tools
Compensate for the weaknesses of the model by feeding it the outputs of other tools. For example, a text retrieval system (sometimes called RAG or retrieval augmented generation) can tell the model about relevant documents. A code execution engine like OpenAI’s Code Interpreter can help the model do math and run code. If a task can be done more reliably or efficiently by a tool rather than by a language model, offload it to get the best of both.
Tactics:
- Use embeddings-based search to implement efficient knowledge retrieval
- Use code execution to perform more accurate calculations or call external APIs
- Give the model access to specific functions
6) Test changes systematically
Improving performance is easier if you can measure it. In some cases a modification to a prompt will achieve better performance on a few isolated examples but lead to worse overall performance on a more representative set of examples. Therefore to be sure that a change is net positive to performance it may be necessary to define a comprehensive test suite (also known an as an “eval”).
Tactic:
Please subscribe to AInsights.
Please subscribe to my master newsletter, a Quantum of Solis.


Brian Solis | Author, Keynote Speaker, Futurist
Brian Solis is world-renowned digital analyst, anthropologist and futurist. He is also a sought-after keynote speaker and an 8x best-selling author. In his new book, Lifescale: How to live a more creative, productive and happy life, Brian tackles the struggles of living in a world rife with constant digital distractions. His previous books, X: The Experience When Business Meets Design and What’s the Future of Business explore the future of customer and user experience design and modernizing customer engagement in the four moments of truth.
Invite him to speak at your next event or bring him in to your organization to inspire colleagues, executives and boards of directors.



Leave a Reply